
Durante muito tempo, a internet foi construída sobre uma ideia que parecia segura: havia endereços IP suficientes para todos. Quando alguém ouve que o IPv4 permite cerca de 4,3 bilhões de endereços, a reação comum é pensar que isso jamais poderia acabar.
Mas acabou.
E não foi por falta de números.
Foi por decisões tomadas lá atrás, quando ninguém imaginava o mundo conectado que existe hoje.
Como um sistema com 4,3 bilhões de endereços conseguiu se esgotar?

Durante muitos anos, quatro bilhões de endereços pareceram mais do que suficientes. O número era grande demais para gerar qualquer preocupação real. Por muito tempo, o espaço IPv4 foi tratado como praticamente inesgotável.
Quando falamos que existem aproximadamente 4,3 bilhões de endereços IPv4 possíveis, esse número ainda soa enorme. Por décadas, ninguém se preocupou seriamente com a possibilidade de esse espaço acabar. Quatro bilhões parecia grande demais para ser consumido.
Na prática, porém, esse espaço se esgotou.
E isso levanta uma pergunta fundamental:
como um número aparentemente tão grande pôde acabar?
Isso não é um problema recente
Se você acha que esse problema surgiu recentemente, não surgiu.
Para entender por que o IPv4 acabou, é preciso voltar ao início da internet, quando decisões que pareciam corretas criaram problemas que só apareceriam décadas depois.
Quando o IPv4 foi criado, no início da década de 1980, a realidade era completamente diferente da atual. A internet era pequena. Poucos computadores estavam conectados. As redes existiam basicamente em universidades, centros de pesquisa e grandes organizações governamentais e corporativas.
Naquele contexto, quatro bilhões de endereços pareciam mais do que suficientes para qualquer projeção razoável.
Ninguém imaginava bilhões de pessoas conectadas.
Ninguém imaginava múltiplos dispositivos por pessoa.
Ninguém imaginava celulares, tablets, sensores, câmeras, carros conectados, relógios inteligentes e uma infinidade de outros equipamentos dependendo de conectividade IP.
Mas o crescimento da internet, por si só, não explica tudo.
Mesmo que a internet tivesse crescido mais lentamente, o modelo original de distribuição de endereços já carregava problemas graves no longo prazo. O ponto central não foi apenas o crescimento, mas a forma como o espaço de endereçamento foi organizado desde o início.
O problema não foi crescimento. Foi o modelo.
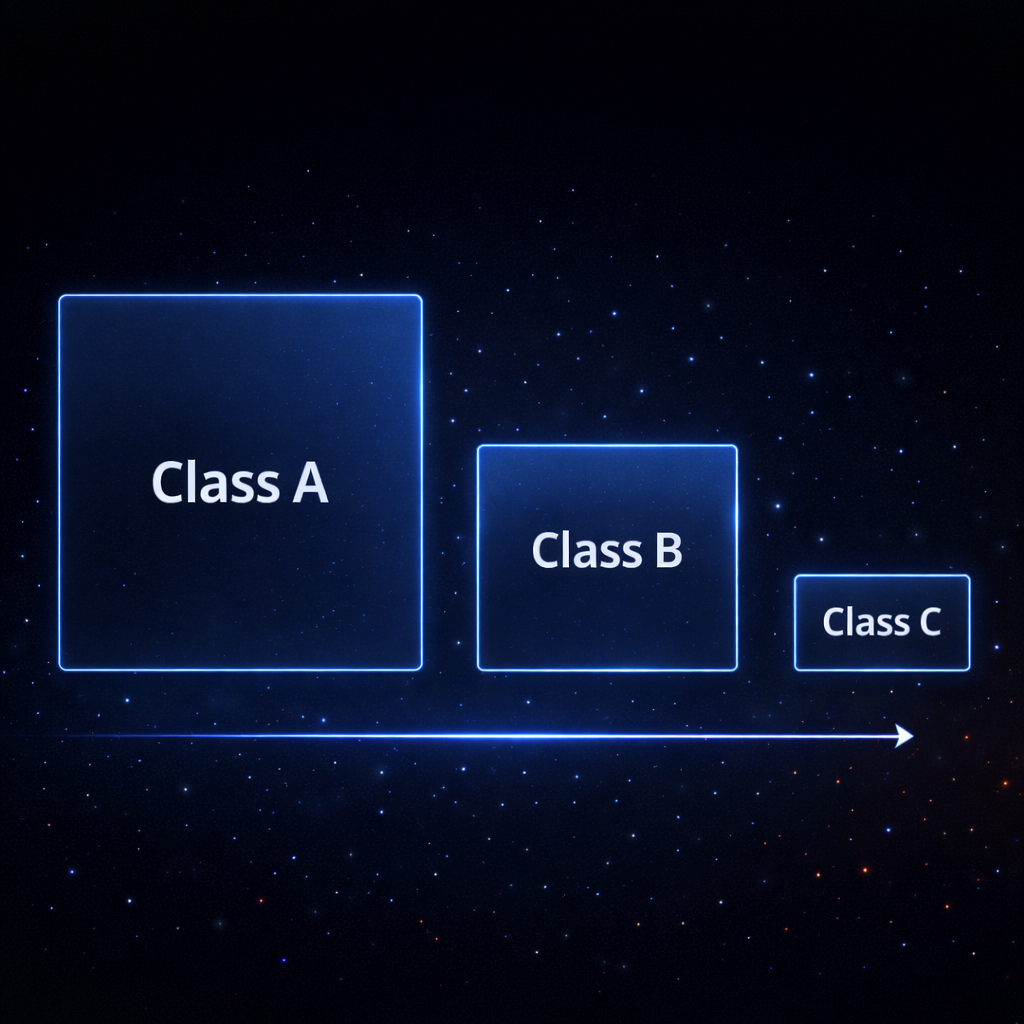
O IPv4 foi estruturado em classes: Classe A, Classe B e Classe C, cada uma com tamanhos de rede muito diferentes.
Essa divisão parecia lógica naquele momento histórico.
Redes grandes para organizações grandes.
Redes médias para organizações médias.
Redes pequenas para redes menores.
Era uma tentativa de simplificar a alocação de endereços em um mundo onde a internet ainda era restrita.
Cada classe possuía uma máscara de sub-rede padrão. Essa máscara determinava quantos bits identificavam a rede e quantos identificavam os dispositivos dentro dela.
No caso de uma rede Classe A, a máscara padrão era 255.0.0.0, o que significava que apenas o primeiro octeto identificava a rede, enquanto os outros três ficavam disponíveis para hosts.
Aqui começa o absurdo

Na prática, uma única rede Classe A criava mais de 16 milhões de endereços IP possíveis.
Agora compare isso com uma rede comum.
Uma rede doméstica típica, usando a máscara 255.255.255.0, funciona perfeitamente com cerca de 254 endereços utilizáveis.
Mesmo ambientes corporativos de médio e grande porte raramente precisam de milhões de endereços em uma única rede.
Ainda assim, no início da internet, grandes organizações receberam redes Classe A inteiras. Empresas como IBM, AT&T, HP, Xerox e outras receberam blocos gigantescos de endereços IPv4.
Naquele momento, isso não parecia um problema. A percepção era de abundância. A lógica era simples: temos muitos endereços, não precisamos economizar.
O resultado foi um desperdício massivo de endereçamento.
Esses blocos enormes não eram usados como uma única rede. As organizações precisavam segmentar, organizar e dividir seus ambientes internos. Para isso, começaram a utilizar máscaras diferentes da máscara padrão da classe.
Subnetting não é o vilão

Subnetting não surgiu para complicar redes.
Ele surgiu porque o modelo anterior desperdiçava endereços.
Subnetting é o processo de dividir uma rede grande em redes menores. Ele não nasceu como uma técnica acadêmica ou teórica, mas como uma necessidade prática. Era preciso administrar melhor um recurso que estava sendo desperdiçado em larga escala.
Quando se utiliza a máscara padrão da classe, estamos falando de endereçamento classful. Quando se utiliza uma máscara diferente da padrão, entramos no conceito de endereçamento classless.
Essa mudança representou um avanço importante. Com o endereçamento classless, tornou-se possível ajustar o tamanho das redes à necessidade real. Redes que antes desperdiçavam milhões de endereços passaram a ser divididas em blocos menores e mais adequados.
Isso não criou novos endereços IPv4.
Mas reduziu drasticamente o desperdício.
Mesmo assim, o problema continuou

Mesmo com subnetting e melhorias no modelo, o problema global persistia.
Além do desperdício causado pelas classes, existiam faixas inteiras de endereços IPv4 que nunca puderam ser usadas na internet pública.
A Classe D foi reservada para multicast.
A Classe E foi reservada para fins experimentais.
Toda a faixa 127.0.0.0/8 foi reservada para loopback.
No caso do loopback, não foi reservado apenas um endereço. Foi reservada uma rede inteira, com mais de 16 milhões de endereços IPv4 que nunca poderiam ser utilizados externamente.
Mais uma vez, uma decisão tecnicamente correta, mas que reduziu ainda mais o espaço efetivamente utilizável.
Somando má distribuição inicial, desperdício, faixas inutilizáveis e crescimento contínuo da internet, o espaço IPv4 se esgotou muito mais rápido do que o esperado.
Não porque quatro bilhões fossem poucos.
Mas porque foram mal administrados ao longo do tempo.
Subnetting não cria endereços

Subnetting não cria endereços.
Ele só reduz desperdício.
Esse ponto precisa ficar muito claro. Subnetting existe para administrar melhor um recurso finito. Ele não resolve o limite global do IPv4.
Para lidar com esse limite, outras soluções precisaram surgir. O CIDR permitiu uma alocação mais flexível. O NAT permitiu que múltiplos dispositivos compartilhassem um único endereço público. E, posteriormente, o IPv6 foi desenvolvido para oferecer um espaço de endereçamento praticamente ilimitado.
Sem entender esse problema, nada do que veio depois faz sentido

Nenhuma dessas soluções pode ser compreendida de forma adequada sem entender o problema original.
Entender por que o IPv4 acabou ajuda a entender por que subnet masks existem, por que subnetting é necessário e por que o endereçamento IP funciona da forma como funciona hoje.
Quando esse contexto fica claro, o estudo de subnetting deixa de ser uma sequência de contas e passa a ser a compreensão de um sistema.
O endereçamento IP deixa de parecer um conjunto de regras arbitrárias e passa a fazer sentido como resposta a decisões tomadas ao longo da história da internet.